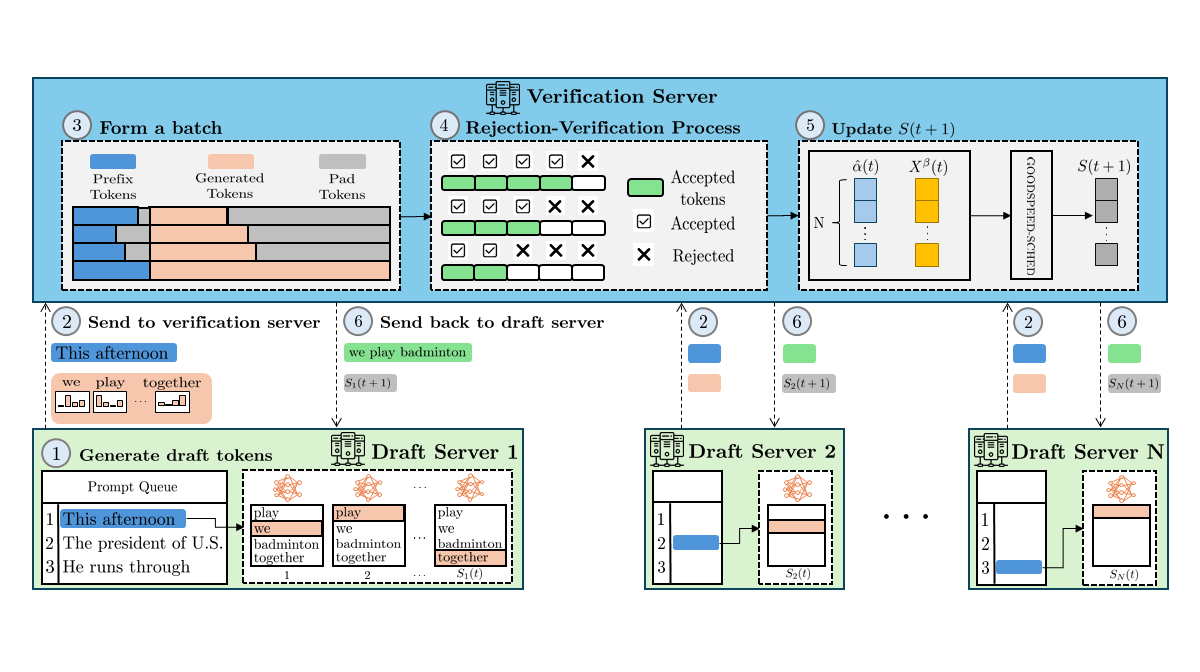
GOODSPEED – Speculative Decoding for Efficient and Fair LLM Inference at the Edge
GOODSPEED is an ongoing research project exploring speculative decoding techniques for efficient large language model inference in distributed edge environments. This project investigates novel approaches to balance inference speed, accuracy, and fairness across heterogeneous edge computing resources.
🚧 Project Status: Currently in active development. Research findings and implementation details will be shared upon completion.
🎯 Research Focus
This project investigates key challenges in deploying large language models at the edge:
- Speculative Decoding Optimization: Exploring techniques to improve token generation speed while maintaining output quality
- Fair Resource Allocation: Developing algorithms to ensure equitable distribution of computational resources across edge clients
- Edge Computing Efficiency: Researching methods to optimize LLM inference in resource-constrained environments
- Distributed System Design: Investigating architectures for coordinated inference across multiple edge nodes
🔬 Research Areas
Inference Optimization
Investigating novel approaches to reduce latency in LLM inference through speculative decoding and related techniques.
Edge Computing
Exploring the unique challenges and opportunities of deploying large models in distributed edge environments.
Resource Fairness
Developing algorithms and frameworks to ensure fair allocation of computational resources across heterogeneous clients.
📚 Related Work
This research builds upon recent advances in:
- Speculative decoding for accelerated inference
- Distributed computing for machine learning
- Edge computing optimization strategies
- Fair resource allocation in distributed systems
📧 Contact
For more information about this research project, please contact the DUAL research group.